季節調整済みARIMAモデルで電力使用状況を推定してみる part2 予測表示
前回の『季節調整済みARIMAモデルで電力使用状況を推定してみる』でARIMAモデルで予測してみましたが、その続きで、予測したグラフを表示方法をもう少し試してみました。
前回
http://jbclub.xii.jp/?p=695
方法はこのARIMA Example 4: ARMAX (Friedman)に記載している通りです。
http://www.statsmodels.org/devel/examples/notebooks/generated/statespace_sarimax_stata.html
2016年12月31日から2017年の1月31日まで予測してみます。
predict_dy = results.get_prediction(start ='2016-12-31', end='2017-1-31') predict_dy_ci = predict_dy.conf_int()
グラフの表示方法です。
# Graph fig, ax = plt.subplots(figsize=(9,4)) npre = 4 ax.set(title='HOKKAIDO POWER', xlabel='Date', ylabel='Power') # Plot data points df.ix['2016-01-01':,'power'].plot(ax=ax, label='Observed') # Plot predictions predict_dy.predicted_mean.ix['2016-12-31':].plot(ax=ax, style='g', label='Dynamic forecast (20161231)') ci = predict_dy_ci.ix['2016-12-31':] ax.fill_between(ci.index, ci.ix[:,0], ci.ix[:,1], color='g', alpha=0.1) legend = ax.legend(loc='lower right')
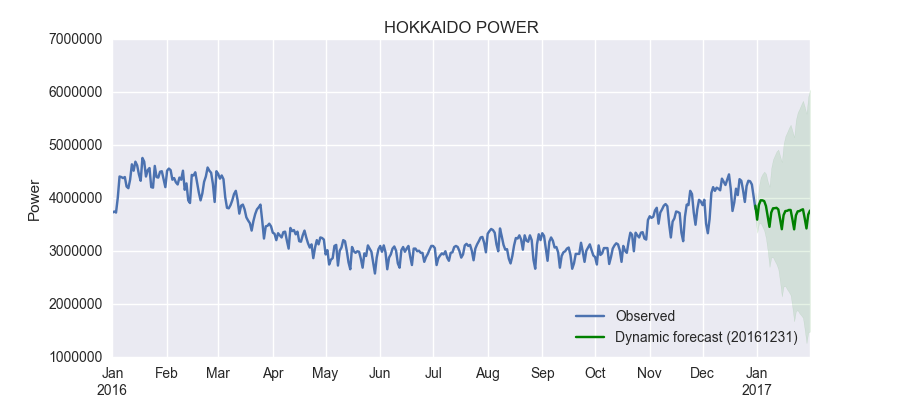
実際に1月以降のデータがどうであったかを確認してみました。
data2 = pd.read_csv("C:\\2017_juyo_hokkaidou.csv", skiprows=3,names=['Date','Time','power'])
data2.index = pd.to_datetime(data2['Date'])
df2 = data2.groupby(data2.index).mean()
df2['power'] = df2.power.apply(lambda x: int(x)*10000)
fig, ax = plt.subplots(figsize=(9,4)) npre = 4 ax.set(title='HOKKAIDO POWER', xlabel='Date', ylabel='Power') df2.ix['2017-01-01':,'power'].plot(ax=ax, label='Observed') legend = ax.legend(loc='lower right')
1月以降のデータがこちらです。
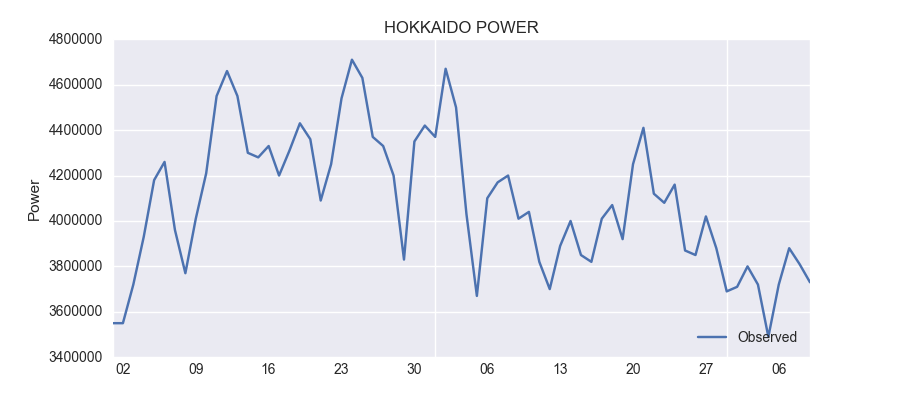
合わせてみるとこうなります。
fig, ax = plt.subplots(figsize=(9,4)) npre = 4 ax.set(title='HOKKAIDO POWER', xlabel='Date', ylabel='Power') df.ix['2016-01-01':,'power'].plot(ax=ax, label='Observed') df2.ix['2017-01-01':'2017-01-31','power'].plot(ax=ax, style='r', label='Observed(JAN)') predict_dy.predicted_mean.ix['2016-12-31':].plot(ax=ax, style='g', label='Dynamic forecast (20161231)') ci = predict_dy_ci.ix['2016-12-31':] ax.fill_between(ci.index, ci.ix[:,0], ci.ix[:,1], color='g', alpha=0.1) legend = ax.legend(loc='lower right')
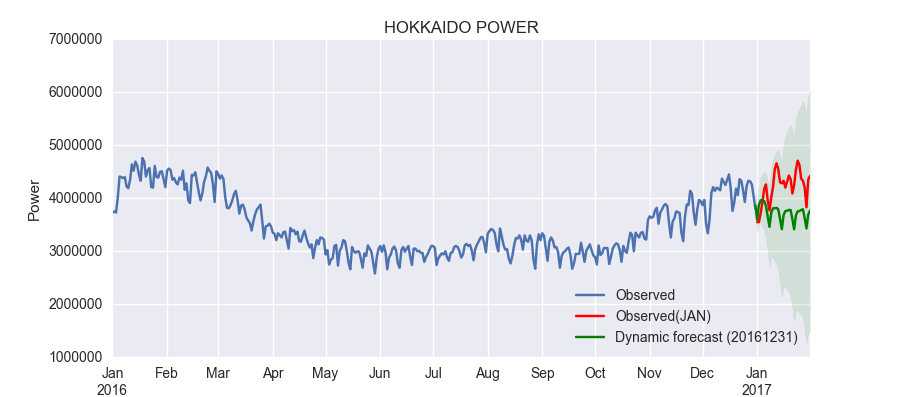
なるほど、95%信頼区間には入っていることがわかりますね。
アップにしたらこうなりました。
fig, ax = plt.subplots(figsize=(9,4)) npre = 4 ax.set(title='HOKKAIDO POWER', xlabel='Date', ylabel='Power') df.ix['2016-12-01':,'power'].plot(ax=ax, label='Observed') df2.ix['2017-01-01':'2017-01-31','power'].plot(ax=ax, style='r', label='Observed(JAN)') predict_dy.predicted_mean.ix['2016-12-31':].plot(ax=ax, style='g', label='Dynamic forecast (20161231)') ci = predict_dy_ci.ix['2016-12-31':] ax.fill_between(ci.index, ci.ix[:,0], ci.ix[:,1], color='g', alpha=0.1) legend = ax.legend(loc='lower right')
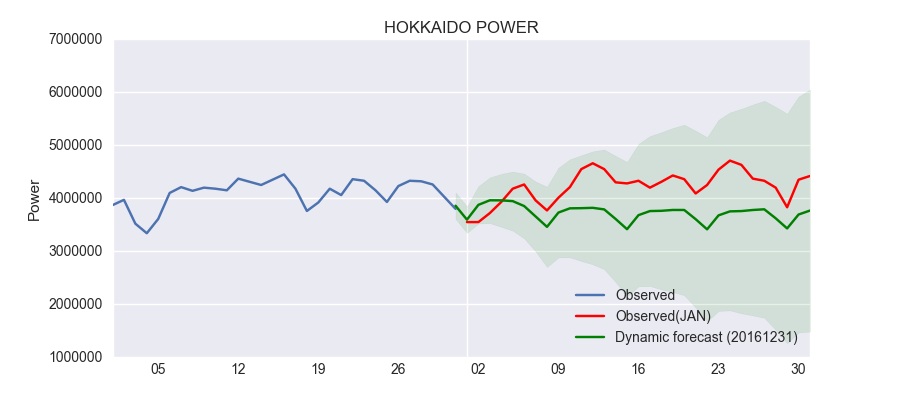
ほほーという感じです。面白いですね!
関連する投稿:
- 2017-03-25:SARIMAX vs. Random Forest Regression -ブログのセッション数の予測-
- 2017-03-09:季節調整済みARIMAモデルで電力使用状況を推定してみる
- 2017-03-17:SARIMAXモデルでPVを予測してみる
- 2017-02-11:Python3でビットコインの回帰線を描いてみる
- 2017-02-24:電力データから季節変動の分解
“季節調整済みARIMAモデルで電力使用状況を推定してみる part2 予測表示” への1件の返信