SARIMAX vs. Random Forest Regression -ブログのセッション数の予測-
興味深い記事を見つけました。
回帰モデルの比較 – ARMA vs. Random Forest Regression
http://qiita.com/TomokIshii/items/b3ebe2b60c5d3d5a0d5a
ARMAモデルと機械学習のRandom Forest Regressionを比較した内容になっていて興味深い内容でした。しかし、このARMAモデルとRandom Forest Regressionモデルの比較では条件が異なっているように思えます。ARMAモデルとRandom Forest Regressionモデルは過去70年のデータから次の30年間の推定値を算出していますが、ARMAモデルは動的予測になっているのに対し、Random Forest Regressionモデルでは観測されたデータをテストデータとして使っているので静的予測になっていると思います。比較するなら合わせるべきだと思います。
この記事を参考にして、SARIMAXを使ったときの予測とRandom Forest Regressionの予測の比較をしてみます。比較対象はブログのセッション数の予測してみます
まずはSARIMAXでの予測です。
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
import seaborn as sns
df = pd.read_csv("C:\\Users\\jbc20170101-20170316s.csv",skiprows=1, names=['Date', 'SESSION']).dropna()
tmd = pd.to_datetime(df['Date'])
df.index = tmd
del df["Date"]
df.plot()
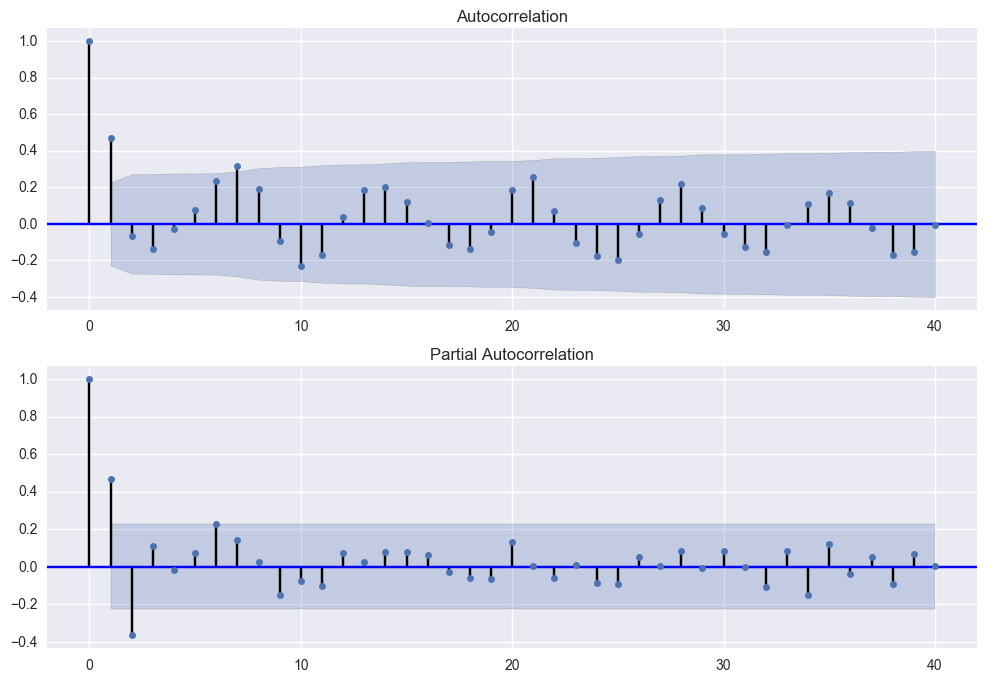
fig = plt.figure(figsize=(12,8)) ax1 = fig.add_subplot(211) fig = sm.graphics.tsa.plot_acf(df['SESSION'], lags=40, ax=ax1) ax2 = fig.add_subplot(212) fig = sm.graphics.tsa.plot_pacf(df['SESSION'], lags=40, ax=ax2)
sarimax_23ct = sm.tsa.statespace.SARIMAX(df['SESSION'], trend='ct', order=(2,0,3)) sarimax_res23ct = sarimax_23ct.fit(disp=False) print (sarimax_res23ct.aic,sarimax_res23ct.bic)
629.519487061 648.059391969
# Dynamic predictions predict_dy = sarimax_res23ct.get_prediction(start='2017-01-01', end='2017/3/31',dynamic='2017/3/16') predict_dy_ci = predict_dy.conf_int() # Graph fig, ax = plt.subplots(figsize=(9,4)) ax.set(title='JBClub SESSION', xlabel='Date', ylabel='SESSION') # Plot data points df.ix['2017/1/1':, 'SESSION'].plot(ax=ax, style='b:', label='Original') # Plot predictions predict_dy.predicted_mean.ix['2017/3/16':].plot(ax=ax, style='g', label='Dynamic forecast') ci = predict_dy_ci.ix['2017/3/16':] ax.fill_between(ci.index, ci.ix[:,0], ci.ix[:,1], color='g', alpha=0.1) legend = ax.legend(loc='upper left')
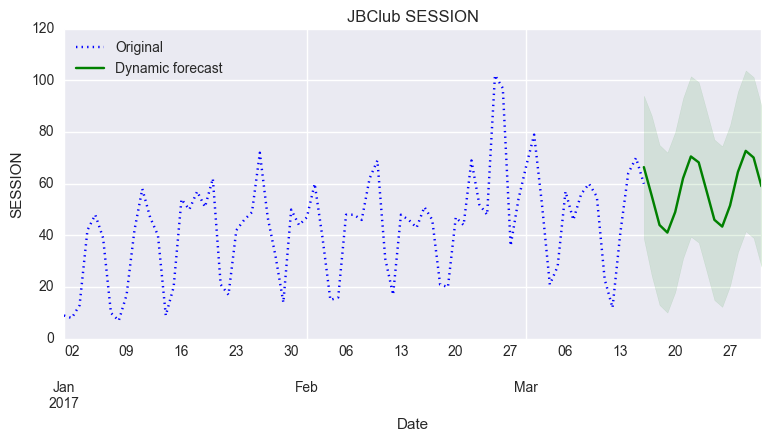
ここまでは前回のやり方と同じです。
ここからランダムフォレストの推定になります。
まだ機械学習やランダムフォレストがなんなのチンプンカンプンな状態なので
「回帰モデルの比較」を参考にしてやってみます。
この記事では予測する1日前と2日前と3日前のデータを訓練データとしています。
データの前処理です。
dates = pd.date_range(start='2017-01-1',end='2017-3-17',freq='D') df2 = pd.DataFrame(index=dates) df2['SESSION'] = df['SESSION'] df2['lag1'] = df2['SESSION'].shift(1) df2['lag2'] = df2['SESSION'].shift(2) df2['lag3'] = df2['SESSION'].shift(3) X_train = df2[['lag1', 'lag2', 'lag3']][3:75].values X_test = df2[['lag1', 'lag2', 'lag3']][75:].values y_train = df2['SESSION'][3:75].values y_test = df2['SESSION'][75:].values
2017年1月1日から3月16日のデータを訓練データとして学習させ、翌日の3月17日のデータを予測します。なので3月16日、15日、14日を使うわけですね。
from sklearn.ensemble import RandomForestRegressor
r_forest = RandomForestRegressor(
n_estimators=73,
criterion='mse',
random_state=1,
n_jobs=-1
)
r_forest.fit(X_train, y_train)
y_train_pred = r_forest.predict(X_train)
y_test_pred = r_forest.predict(X_test)
y_test_pred
Out[12]:
array([ 45.5890411])
3月17日は45.58という結果が得られました。
推定値をグラフにしてみます。
predict = np.r_[y_train_pred,y_test_pred] df3=pd.DataFrame(predict,index = df2.index[3:],columns=['y_train_pred']) df2['SESSION']['2017-03-17']=y_test_pred[0] px = df2.index py1 = df2.SESSION plt.plot(px, py1, 'b:', label='Original') px_in = df3.y_train_pred.index plt.plot(px_in, df3.y_train_pred, 'g',label='Random F.Reg.') plt.legend() plt.grid(True) plt.show()
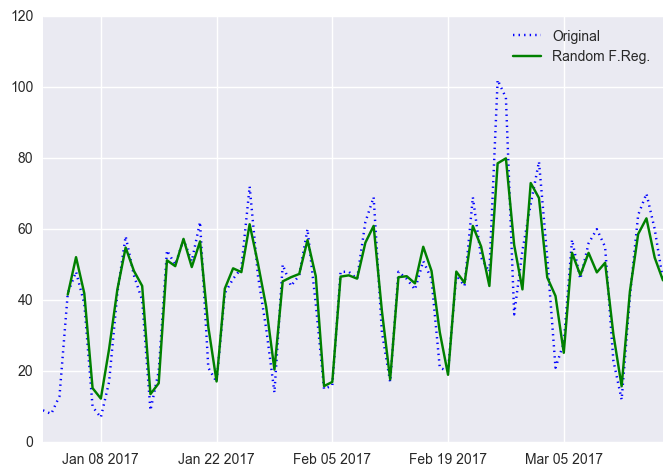
更に3月17日の予測値を使って3月18日、3月18日の予測値を使って3月19日とやって、3月31日まで予測してみます。
pdate = pd.date_range(start='2017-03-18',end='2017-3-31',freq='D') for t in pdate: dates = pd.date_range(start='2017-01-1',end=t,freq='D') df4 = pd.DataFrame(index=dates) df4['y_train_pred'] = df3['y_train_pred'] df4['SESSION'] = df2['SESSION'] df4['lag1'] = df4['SESSION'].shift(1) df4['lag2'] = df4['SESSION'].shift(2) df4['lag3'] = df4['SESSION'].shift(3) X_test = df4[['lag1', 'lag2', 'lag3']].ix[t].values y_test_pred = r_forest.predict(X_test) #機械学習で値を予測 predict = np.r_[predict,y_test_pred] #予測値をマージ df3=pd.DataFrame(predict,index = df4.index[3:],columns=['y_train_pred']) df2['SESSION'][t]=y_test_pred[0]
グラフにしてみます。
px = df2.ix['2017-01-01':'2017-03-16'].index py1 = df2.ix['2017-01-01':'2017-03-16'].SESSION plt.plot(px, py1, 'b:', label='Original') px_in = df3.ix['2017-03-16':'2017-03-31'].y_train_pred.index plt.plot(px_in, df3.ix['2017-03-16':'2017-03-31'].y_train_pred, 'limegreen',label='Random F.Reg.') plt.legend() plt.grid(True) plt.show()
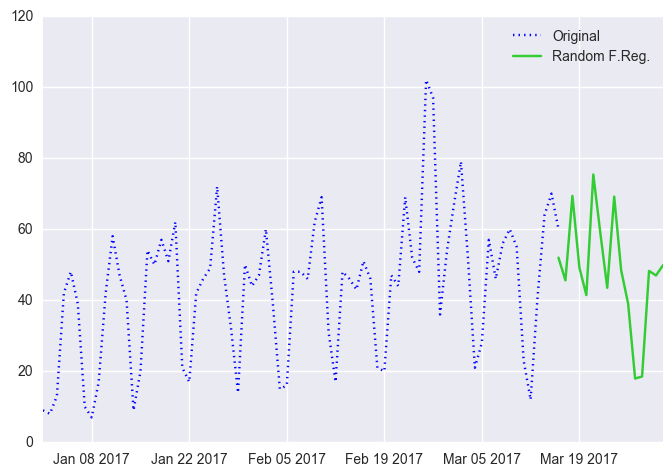
SARIMAモデルとRandom Forestモデルを合わせてグラフにしてみます。
# Graph fig, ax = plt.subplots(figsize=(9,4)) #fig, ax = plt.subplots() ax.set(title='JBClub SESSION', xlabel='Date', ylabel='SESSION') # Plot data points df.ix['2017/1/1':, 'SESSION'].plot(ax=ax, style='b:', label='Original') # Plot predictions predict_dy.predicted_mean.ix['2017/3/16':].plot(ax=ax, style='g', label='Dynamic forecast') ci = predict_dy_ci.ix['2017/3/16':] ax.fill_between(ci.index, ci.ix[:,0], ci.ix[:,1], color='g', alpha=0.1) # Plot predictions Random df3.ix['2017-03-16':'2017-03-31'].y_train_pred.plot(ax=ax, style='limegreen',label='Random F.Reg.') legend = ax.legend(loc='upper left')
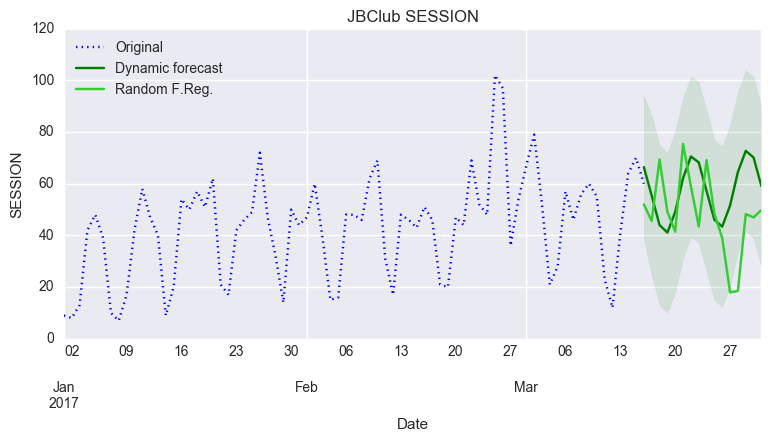
なかなか興味深いです。モデル精度比較はつかれちゃったのでやめておきます。
※参考 One step forcast and Dinamic Forcast
http://www.statsmodels.org/devel/examples/notebooks/generated/statespace_sarimax_stata.html
※回帰モデルの比較 – ARMA vs. Random Forest Regression
http://qiita.com/TomokIshii/items/b3ebe2b60c5d3d5a0d5a
関連する投稿:
- 2017-03-14:季節調整済みARIMAモデルで電力使用状況を推定してみる part2 予測表示
- 2017-03-17:SARIMAXモデルでPVを予測してみる
- 2017-02-24:電力データから季節変動の分解
- 2014-08-23:Pythonで回帰分析 (身長と体重の関係、PVとセッションの関係)
- 2017-02-11:Python3でビットコインの回帰線を描いてみる
SARIMAX VS. RANDOM FOREST REGRESSION
の RANDOM FOREST REGRESSIONのコードをコピーして使わせてもらえないでしょうかーーー。
同じようなコードがーーgoogle検索 機械学習で
金相場を予想する(藤川)番外編にあります
金相場データ(日時‐―終値ーー)を予想(グラフがフイツトする?)したいのですが
お願い出来ればと思いメール
しました
Windows10 バイソン3.7
函館市大森町 西野(84さい)f7222227@yahoo.co.jp
コメントありがとうございます。
コードについて使って頂いて大丈夫です!
返信ありがとうございます
f7222227@yahoo.co.jp 西野