今年もまた、みたけ山トレイルランに参加するのですが、再び以前の記録の分布をみてみたくなりましたので、
違う方法で再度ヒストグラムにしてみます。
今回は”Think Stats 第2版 ―プログラマのための統計入門”で提供されているコードを使いました。
ThinkStats2のコードは以下からダウンロードできます。
https://github.com/AllenDowney/
以前のヒストグラム
http://jbclub.xii.jp/?p=532
準備
from pandas import Series, DataFrame import pandas as pd import numpy as np %pylab
thinkstats2のimport
cd C:\ThinkStats2-master\code import thinkstats2 import thinkplot
データの取り込み
tm = pd.read_csv('C:\work\mitake\mitake2.csv',skiprows=1, names=['Rank', 'No','FamilyName','FirstName','Age','Sex','Pref','Time'], encoding='utf-8')
時間の変換
tmd = pd.to_timedelta(tm['Time'])
ここまでは以前と同じです。
#データフレーム化
df = DataFrame(dict(A=tmd))
df['B'] = df['A'] / pd.to_timedelta('00:05:00') // 1
df['C'] = df['B'] * pd.to_timedelta('00:05:00')
df.head(10)
Out[28]:
A B C
0 01:05:03 13.0 01:05:00
1 01:07:10 13.0 01:05:00
2 01:07:52 13.0 01:05:00
3 01:12:00 14.0 01:10:00
4 01:12:14 14.0 01:10:00
5 01:12:31 14.0 01:10:00
6 01:12:54 14.0 01:10:00
7 01:13:23 14.0 01:10:00
8 01:13:44 14.0 01:10:00
9 01:13:54 14.0 01:10:00
Aは元の時間のデータです。
BはAを5分で割った値の整数部分です。今回5分毎のヒストグラム(5分事の時間帯に何人いるのか)を出すため5分で割っていますが、10分毎にするなら10分で割ります。
CはBに再度掛け算しています。この値が、その人がどの時間帯に属するかを示しています。
ここが一番引っかかったところで、インデックスされている時間を再サンプリングするやり方はresampleメソッドを使って簡単にできるのですが、時間データの変換をどうするかよくわからず、こういうやり方になってしまいました。うまいやり方があればどなたか教えてほしいです。
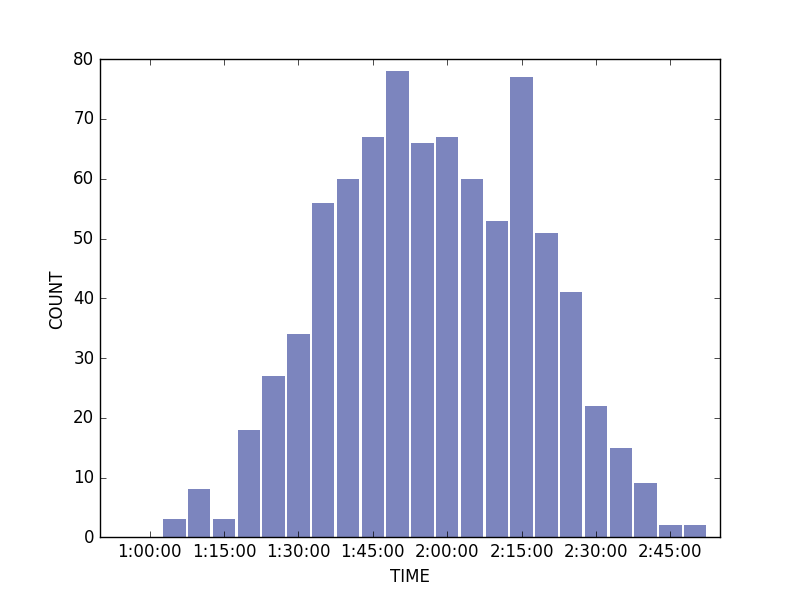
ここでthinkstats2のクラスHistをつかってヒストグラムを作成し、thinkplotでグラフ化します。
hist = thinkstats2.Hist(df['B']) thinkplot.Hist(hist)
グラフ化の体裁を整えます。
plt.xticks([12.5, 15.5, 18.5, 21.5, 24.5,27.5,30.5,33.5], ['1:00:00','1:15:00','1:30:00','1:45:00','2:00:00','2:15:00','2:30:00','2:45:00'])
plt.xticks([12, 15, 18, 21, 24,27,30,33], ['1:00:00','1:15:00','1:30:00','1:45:00','2:00:00','2:15:00','2:30:00','2:45:00'])
plt.xlabel('TIME')
plt.ylabel('COUNT')
これでいったんできました。
以前の図とおんなじですね。
http://jbclub.xii.jp/?p=532
以上
{kind=link}
View Comments