季節変動のあるデータから季節変動を分離する方法のメモです。
Rでは季節変動のあるデータからstl関数を使って季節変動を簡単に分離できるらしいのですが、
pythonでも同じようにできるみたいなのでやってみました。
データは北海道電力の電力使用状況をダウンロードしてみました。
%matplotlib inline
import datetime as datetime
import matplotlib.pyplot as plt
import pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
data = pd.read_csv("http://denkiyoho.hepco.co.jp/data/2016_juyo_hokkaidou.csv", skiprows=3,names=['Date','Time','power'])
data.index = pd.to_datetime(data['Date'])
df = data.groupby(data.index).mean()
df.plot(color="darkblue")
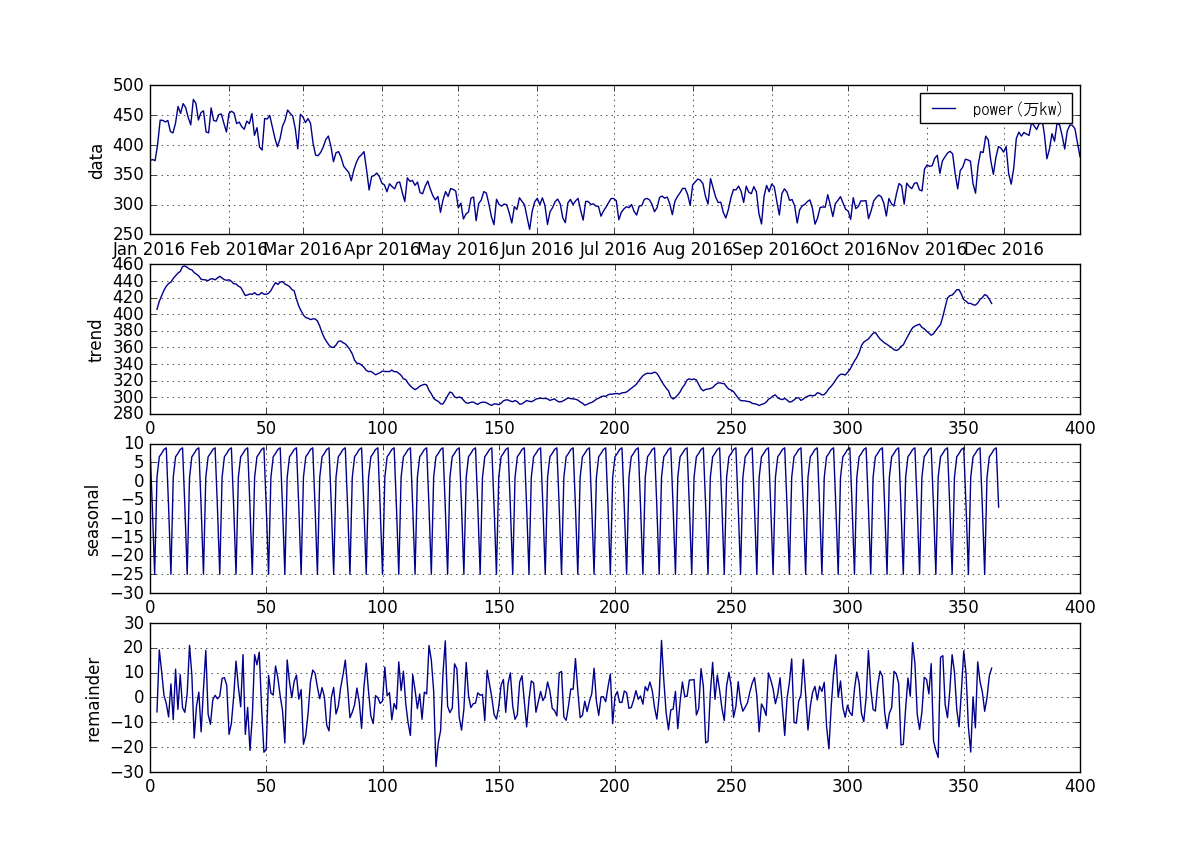
まずは電力使用量のデータをグラフにしてみました。冬は電力使用量が上がっていることが分かりますね。ちなみに単位は万kWです。ここからトレンド、季節変動、、残差(ランダム成分)にわけます。
dataFrame = pd.DataFrame(df['power'].values.astype(int), pd.DatetimeIndex(start='2016-01-01', periods=len(df['power']), freq='D')) ts = seasonal_decompose(dataFrame.values, freq=7) plt.plot(ts.trend) # トレンド成分 plt.plot(ts.seasonal) # 季節成分 plt.plot(ts.resid) # ノイズ成分
これでトレンド、季節変動、、残差(ランダム成分)に分離できました。
グラフでまとめるとこんな感じです。
横の数値があっていないのがイマイチですね。
■グラフ生成
from matplotlib.font_manager import FontProperties
fp = FontProperties(fname='C:\Windows\Fonts\HGRGM.TTC')
fig = plt.figure(figsize=(12,10))
ax1 = fig.add_subplot(4,1,1)
plt.ylabel('data')
ax2 = fig.add_subplot(4,1,2)
plt.ylabel('trend')
ax3 = fig.add_subplot(4,1,3)
plt.ylabel('seasonal')
ax4 = fig.add_subplot(4,1,4)
plt.ylabel('remainder')
y1 = df['power']
y2 = ts.trend
y3 = ts.seasonal
y4 = ts.resid
ax1.plot(y1,label=u'power(万kw)',color="darkblue")
ax2.plot(y2,label='trend',color="darkblue")
ax3.plot(y3,label='seasonal',color="darkblue")
ax4.plot(y4,label='remainder',color="darkblue")
ax1.grid()
ax2.grid()
ax3.grid()
ax4.grid()
ax1.legend(prop=fp,loc='upper right')
つぎはARIMAモデルを推定してみたいと思います。
■参考
時系列分析入門~季節調整モデル編~ RとPythonで実装
http://qiita.com/dr_paradi/items/b279de980268e1dc114a
Rで季節変動のある時系列データを扱ってみる
http://tjo.hatenablog.com/entry/2013/10/30/190552
電気量
http://denkiyoho.hepco.co.jp/download.html
{kind=link}
{kind=link}